YAML для пайплайны
YAML пайплайна предоставляет комплексный обзор всей конфигурации вашего пайплайна в формате YAML. Это включает все ноды с их расположением, исполняемым кодом, взаимосвязями и различной технической информацией, которая определяет, как работает пайплайн.
Доступ к YAML пайплайна
Чтобы получить доступ к конфигурации YAML пайплайна:
- Нажмите кнопку More в интерфейсе пайплайна
- Выберите YAML из выпадающего меню
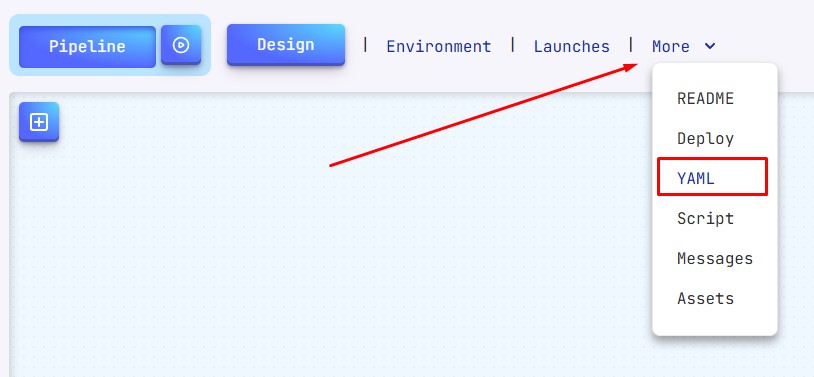
Это откроет редактор YAML, где вы можете его просматривать и изменять.
Структура YAML
YAML пайплайна следует определенной иерархической структуре:
1. Метаданные пайплайна
name: Pipeline Name
version: 1
description: Pipeline description
readme: {}
category:
_id: category_id
title: Category
Этот раздел содержит базовую информацию о пайплайне, включая название, описание и категоризацию.
2. Конфигурация запуска
start:
nodes:
- first_node_id
Определяет, какая нода служит стартовой точкой для выполнения пайплайна.
3. Входы и выходы
inputs:
string1:
title: String 1
type: string
# Параметры входных данных
outputs:
json_output:
title: JSON
type: json
# Параметры выходных данных
Здесь определены все входы и выходы для всех нод, размещённые на рабочем пространстве пайплайны.
4. Потоки (соединения нод)
flows:
connection_name:
from: source_node
output: output_parameter
to: target_node
input: input_parameter
Этот раздел описывает, как данные передаются между нодами, связывая выходы одной ноды с входами другой.
5. Конфигурация нод
nodes:
node_id:
version: 1
title: Node Title
source: node|catalog
execution: rapid|regular|deferred|protracted
script: |
// JavaScript код
inputs:
# Определения входов ноды
outputs:
# Определения выходов ноды
arrange:
# Расположение ноды
Каждая нода в пайплайне полностью описана со всеми параметрами и кодом.
Редактирование и сохранение
При внесении изменений в YAML пайплайна:
- Внесите свои изменения в редакторе YAML
- Нажмите Save внизу интерфейса
- Проверьте индикатор состояния - зеленый индикатор "Saved" появится справа, если нет ошибок
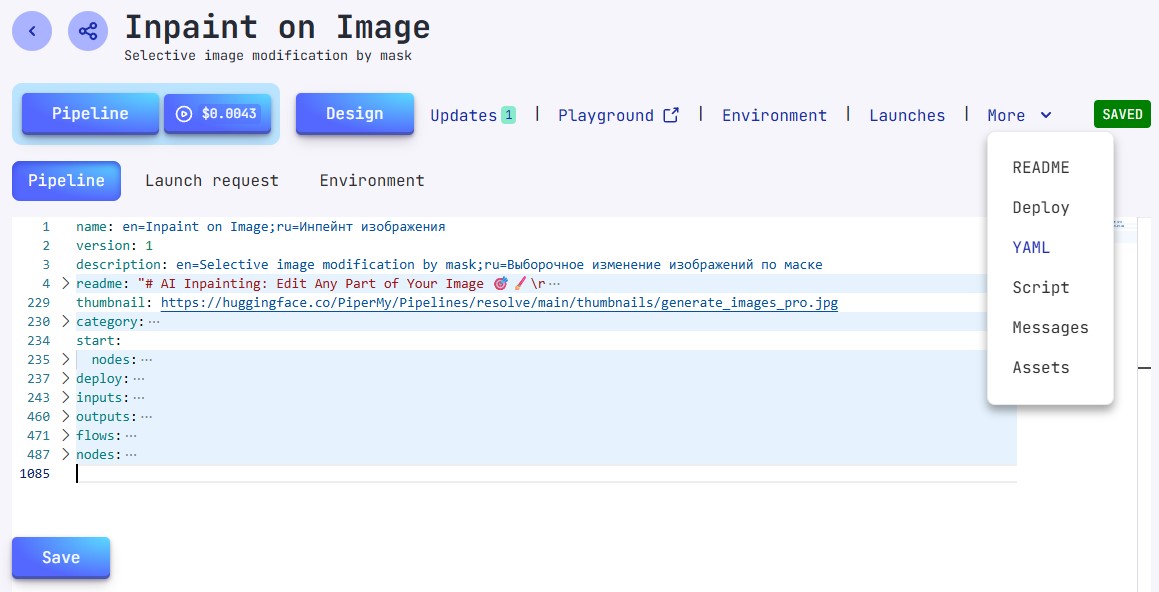
Любые синтаксические ошибки или проблемы конфигурации будут выделены, предотвращая операцию сохранения до их устранения.
Возврат в рабочее пространство пайплайна
Чтобы вернуться в визуальное рабочее пространство пайплайна:
- Нажмите синюю кнопку Pipeline слева в интерфейсе
Это переключит вас обратно в графический редактор пайплайна.